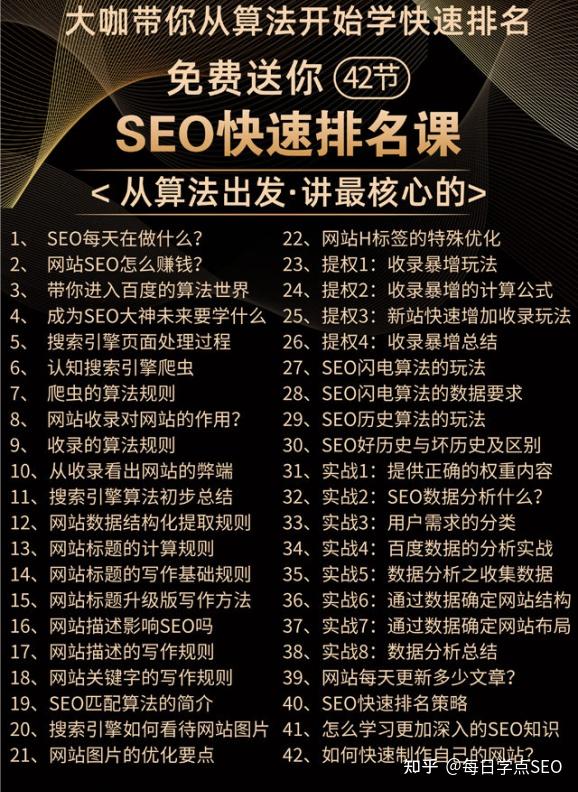
摘要:xml格式文件,里面包含有网站所有的网站,我们可以通过它来向搜索引擎提交网业地址,同时我们也可以在它身上下功夫,这里我使用的网站地图文件为老虎地图所制作。考虑到大部分大佬哥的网站链接推送数量可不少,这里应用了线程池的技术,多线程推送网址,比较简单,复制粘贴即可完成!
在互联网技术飞速发展的当今社会,网站收录已成为了广大站长最为关注的焦点议题之一。尤其对位于国内市场主导搜索引擎地位的百度而言,其收录情况直接影响网站的流量和知名度。然而,在实际运营中,诸多站长仍面临着百度收录难题。幸运的是,百度官方推出了普通收录和快速收录两种模式,通过调用相应的API接口,可以有效提升网站的收录效率。本文将深入探讨如何利用百度官方API接口解决网站收录问题,并分享一些实用的优化策略与技巧。
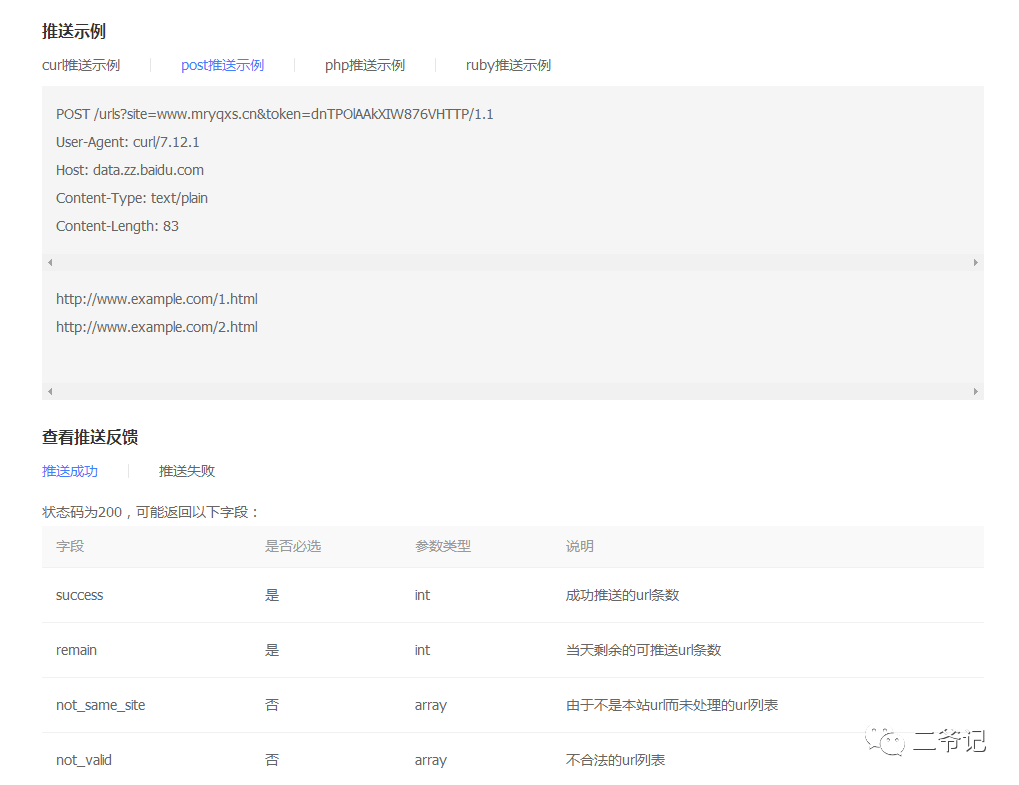
普通收录与快速收录
Google为站长提供两个收录方式——常规收录和快速收录,以满足不同需求。前者是按照常规步骤百度收录提交软件,将网址传送至百度服务器等待自然抓取收录;而后者则通过使用官方API接口功能,迅速向百度服务器发送网页链接地址,从而加速收录过程。相比而言,快速收录能让页面尽早被搜索引擎发现并索引,提高网站内容的检索效率。
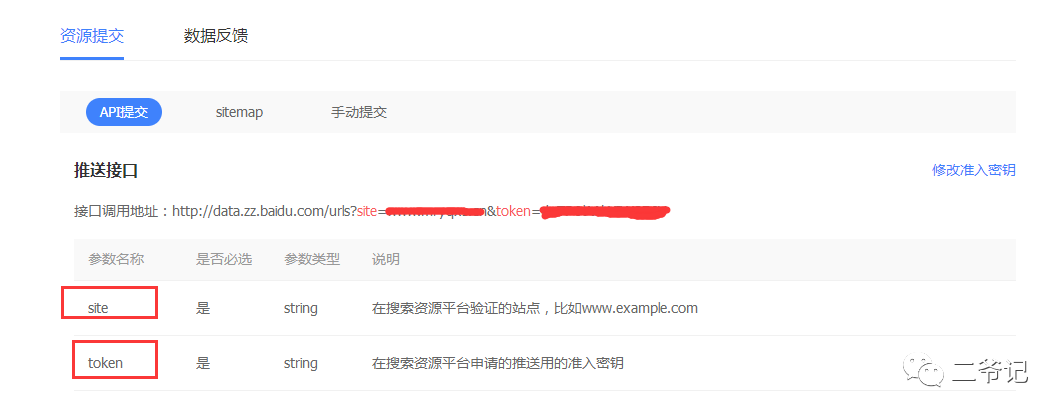
调用官方API接口实现快速收录
利用百度官方API实现网页快速收录并不复杂,只需要参照官网提供的示例和参数设置进行相应的调整即可成功提交。站长们可查阅官方文档,根据自身需求调整API调用以完成网页提交。提交完成后,请耐心等待百度搜索引擎对网页进行深入处理并编入索引。虽然API接口能够提高收录效率,但页面质量及原创性仍是关键因素,只有高质量的内容才能获得更好的排名。
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json
def api(site,token,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url=f"http://data.zz.baidu.com/urls?site={site}&token={token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response=requests.post(post_url,headers=headers,data=url)
req=response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json=json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
优化网站地图提升收录效果
除了API接口之外,对网站地图的优化也是提升收录效率的重要方式。作为整合所有页面链接地址的XML文件——sitemap.xml,它能够协助搜索引擎快速准确地解读和收集网页内容信息。尤其在规模较大且页面复杂的网站中,全面且详尽的地图链接能帮助搜索引擎更好地把握全局,从而提升整个网站的收录效果。
利用正则表达式处理sitemap.xml文件
在站点地图优化过程中,使用正则表达式从sitemap.xml文件提取页面链接地址至关重要,使得链接信息处理更为灵活。正则表达式是强大且高效的文本匹配器,方便我们获取和解析所需信息。借助这一工具,我们能够精准提取sitemap.xml中的链接地址,为后续工作打下坚实基础。
多线程推送网址加速收录
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
鉴于众多站长需要同时向搜索引擎发送多页链接以便被编入索引,我们推荐采用线程池技术实现多线程网页推送,从而提高推送效率。通过使用线程池,可以并行处理多个任务,并将任务分配给空闲的线程进行执行,极大地加速了推送过程。这种方法操作简便,只需简单复制粘贴代码即可完成相应设置,显著提升推送效率和成功率。
总结与展望
本篇文章针对百度官方API接口优化、网站地图调整以及多线程推送这三项策略进行深度解析百度收录提交软件,旨在破解百度收录难题。借助适当的策略和技术手段,网站管理员可有效提升页面在搜索引擎中的可见度和排名。展望未来,随着科技飞速发展,相信百度收录问题的解决方案会更趋便捷与高效。
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")