摘要:搜索引擎工作过程非常复杂,今天和大家分享一下我所了解的百度蜘蛛是怎么实现网页收录的。当蜘蛛在爬行和抓取一个网页的内容时,会进行一定程度的复制内容检测,如果网页所在的网站权重低,而且大部分文章都是抄袭来的话,蜘蛛就很可能不喜欢你的网站了,不在继续爬行,也就不收录你的网站。
在互联网信息爆发式增长背景下,搜索引擎已然成为了人们学习新知和解决难题的重要工具。然而,这类系统的运作原理却颇为复杂,如百度的爬虫(Spider)运作模式就备受关注。此文旨在解析百度爬虫如何完成网页信息的搜集过程,涵盖了蜘蛛的爬行、页面内容抽取及关键词索引的建立等诸多环节,带领大家一探搜索引擎的核心技术秘密。
蜘蛛爬行抓取
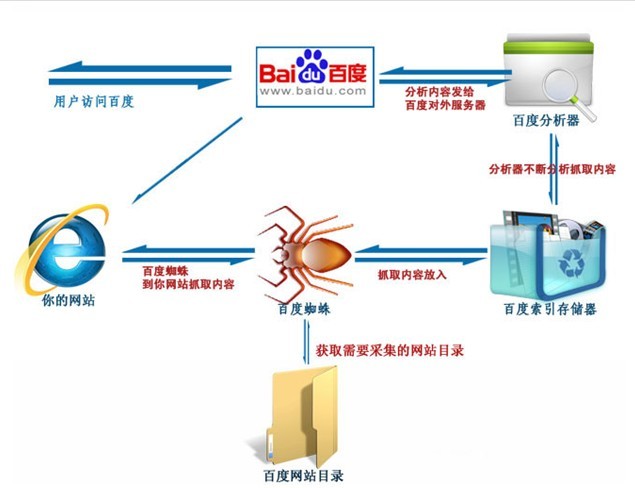
搜索引擎建立初始阶段,首要环节便是利用精密的蜘蛛软件对全球网页深入挖掘,此乃其技术关键所在。“蜘蛛”像是探险家,于错综复杂的互联网上随链条进退,穿越各大网站,持续收集各类信息。以百度搜索引擎的"百度蜘蛛"为例,它在访问任意网页时,先查看该页的robots.txt文件——即一种告知蜘蛛何时可采集何类页面信息的规范文档。若无禁令,蜘蛛将从当前页面出发,循着页面内的链接逐一追索,宛如在巨型网络地图上游走,逐步扩大搜索范围。
1、蜘蛛爬行抓取。 2、信息过滤。 3、建立网页关键词索引。 4、用户搜索输出结果。
蜘蛛并非全面摄入信息,而是采取特有的策略和手段对信息进行甄别,确定其优先级。在寻找并抓取页面的过程中,蜘蛛依内容判断网页优劣,例如检验有无剽窃行为等,从而评价网页的价值及影响力。倘若发现网站内容多为盗版或声誉欠佳,蜘蛛便有可能暂停采集此网站页面,以此确保搜索结果之高质及精准。
建立网页关键词索引
抓取完网页后,蜘蛛的下一步任务是构建关键字索引表。它会深入分析页面文本,通过分词技术化为关键词,然后录入索引表格中。这个步骤既满足了用户的检索需求,也提高了搜索引擎的效率。正向索引为网页内容和关键词搭建了桥梁;反向索引则利用关键词查询关联网页信息。
用户搜索关键词时,搜索引擎借助索引表进行精准匹配,找寻相关网页。接着,运用复杂算法对网页进行综合评分,排列出搜索结果顺序。这需历经诸多精密计算与策略制定过程,以确保结果关联度高且准确可靠。
搜索引擎的未来
随着人工智能及大数据技术不断发展,搜索引擎呈现智能化、个性化趋势,未来能深入洞察用户需求,提供精准检索结果。同时,搜索引擎日益重视优质原创内容,对于低质抄袭内容采取更为严格的筛选和惩罚措施。
在网络不断创新发展中,搜索引擎面对前所未有之机遇和挑战。以移动互联网为例,它改变了搜索需求,使得其更加多元化且具有时效性,因而需要搜索引擎迅速敏捷地调整。此外,诸如语音搜索、图像搜索等新型技术为搜索引擎开辟了全新的发展空间。
结语
搜索引擎的运转体系错综复杂,既为其优点同时也带来挑战,使得我们得以在海量数据中迅速获取所需。而搜索引擎的核心——蜘蛛程序,正是承担着信息收集和整理的重任百度蜘蛛抓取但是不收录一个月了,以全面提高我们追求效率的方式。尽管如此,在搜索引擎的运作过程中依然存在许多问题和挑战,有待我们进行更深度的研究并寻求创新性的解决方案。
随着科技与社会进步的不断发展,搜索引擎必将日趋智能化和人性化,从而为广大用户带来更便捷以及丰富多样的生活体验。与此同时,我们必须谨慎对待搜索引擎所采用的技术与算法,确保其检索结果的公正性和准确性。普通用户可以通过贡献高质量的原创内容来推动搜索引擎的持续升级和完善。
在这个充斥着信息的社会里,搜索引擎已成为我们获取知识与解答疑虑的重要媒介。本文旨在深入解析搜索引擎的运行原理百度蜘蛛抓取但是不收录一个月了,并期待您继续关注我的博客,共同探讨搜索引擎技术的深度运用。